🗓️ Week 14
Trying IPC
My script runs two tasks: one logs transaction summaries, and the other traces memory usage.
So far, I have optimized my script for HTTP. However, since I will be running it on a local machine that operates a node, IPC (Inter-Process Communication) offers a direct connection without all the overhead from HTTP payloads. It’s like plugging into the heart of the node. Web3.py advertises IPC as the fastest mode:

A couple of hours later, I wired IPC into my script using Web3.py and hit run. The first task was successful and noticeably faster. But then the second task failed. Debugging this engulfed my entire week.
Timeout!
The second task fails after 30 seconds with a timeout error.

The IPC integration isn’t completely broken; otherwise, the first task wouldn’t have succeeded. I read the documentation again and then dove into the Web3.py source code. I found an alternative way to make a request using a coroutine. I tried again.
Timeout!Maybe the optimization pipeline is messing with IPC. I disabled it.
Timeout!Web3.py provides access to the underlying socket, bypassing all the formatting fluff. I tried once more.
Timeout!At this point, I was questioning whether I should change my profession and move to a new country. But I skipped Web3.py altogether and attempted to write my own socket client. Halfway through, I realized what the problem was.
HTTP pads messages with metadata, such as the length of the message. This encoding during sending and decoding during reception creates an overhead.
IPC, on the other hand, just streams messages—nothing else. That’s why IPC is considered "faster" than HTTP. Here’s the catch:
- IPC sends data in small chunks (4KB chunks in the case of Web3.py).
- These chunks do not respect message boundaries. The client has to figure out the boundaries of individual messages from the chunks.
In essence, it’s like assembling a book page by page without knowing when one book ends and another begins. The client has to piece together the chunks and identify message boundaries. This works fine for small messages, which is why my first task passed.
However, my second task contained a 19MB message sent in 4KB chunks via IPC. Web3.py attempts to recover the message with each chunk—a total over 4 thousand times.
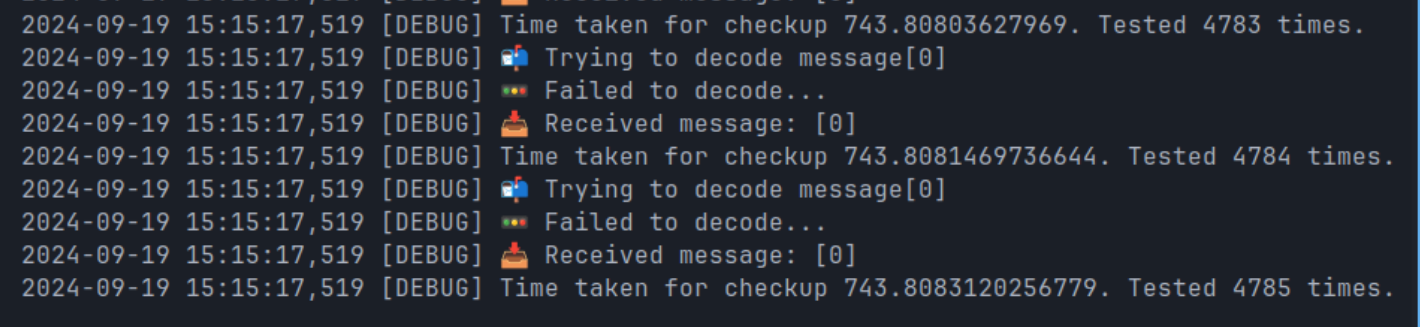
The entire thing takes about 12 minutes; well over the default 30 second timeout. The timeout error was screaming at me the whole time, but I refused to believe that IPC could be slow?! For comparison HTTP takes about 300ms.

Well.
What could be done? Maybe adding information about message boundaries as part of the incoming message so we don’t have to keep guessing?
This is exactly what HTTP does with its metadata.
Post-betrayal, I awkwardly roll back to HTTP (luckily protocols don't hold grudges!)
I also raised this issue to web3.py and they were super cool about it.
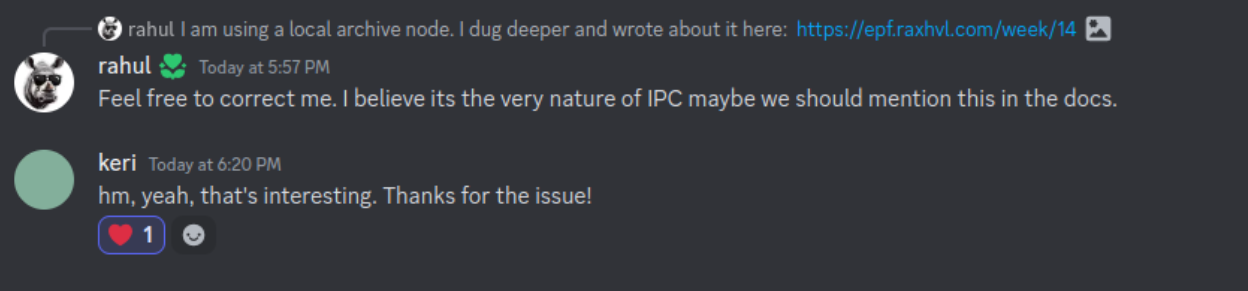
TL;DR: As of now, IPC works faster for small payloads where HTTP has an overhead, but for larger messages, it’s the other way around.
Update: The issue has been fixed..