🗓️ Week 13
I'm fully aware that the script I wrote last week is not scalable. My goal is to fix it (and also apologize to Dijkstra):
“I mean, if 10 years from now, when you are doing something quick and dirty, you suddenly visualize that I am looking over your shoulders and say to yourself 'Dijkstra would not have liked this', well, that would be enough immortality for me.”
― Edsger W. Dijkstra
HTTP golfing
The script is slow because I/O operations blocks execution. We run a little experiment.
Setup a mock transaction API that takes about to finish:
from flask import Flask, jsonify
from time import sleep
app = Flask(__name__)
@app.route('/transaction/<int:id>', methods=['GET'])
def get_transaction(id):
# Simulate a 200ms delay
sleep(0.2)
# Return a fake transaction
tx = {
"nonce": id,
"block": 9000,
"from": "0x0000000000000000000000000000000000000001",
"to": "0x0000000000000000000000000000000000000002",
"input": "0xdeadbeef"
}
return jsonify(tx)
if __name__ == '__main__':
app.run(port=8000)Let's get 10 transactions:
import requests
url_list = [f"http://localhost:8000/transaction/{i}" for i in range(1, 100)]
def sync():
for url in url_list:
with requests.Session() as session:
if session.get(url).status_code != 200:
raise Exception(f"Request {url} not successful!")
sync()As expected, Hyperfine reports the script takes about to complete:

No prizes for guessing that 100 requests takes :

A million requests takes . Wow, we’re really setting records here. Can we do better?
I/0 operations are blocking because the CPU idles waiting for the request to complete.
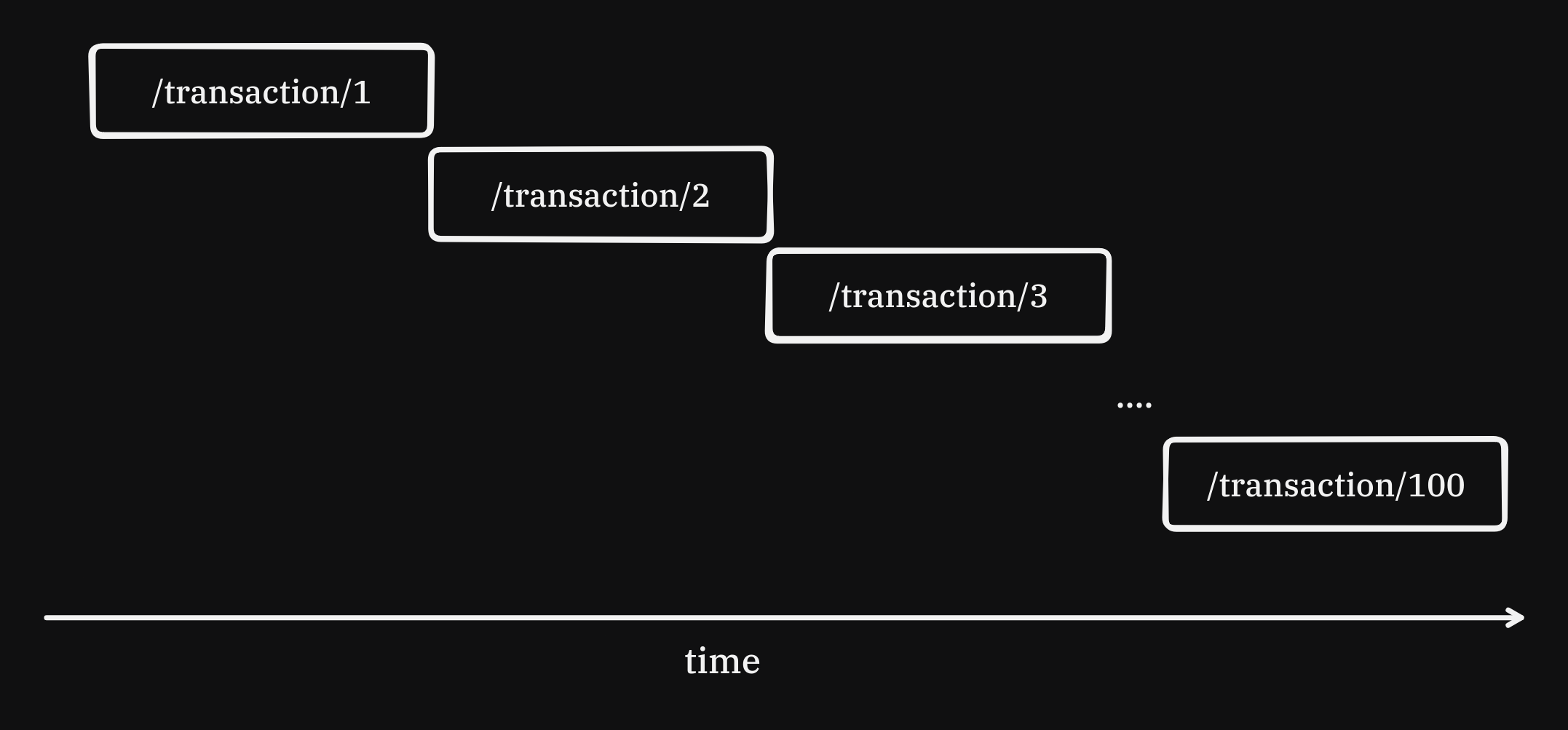
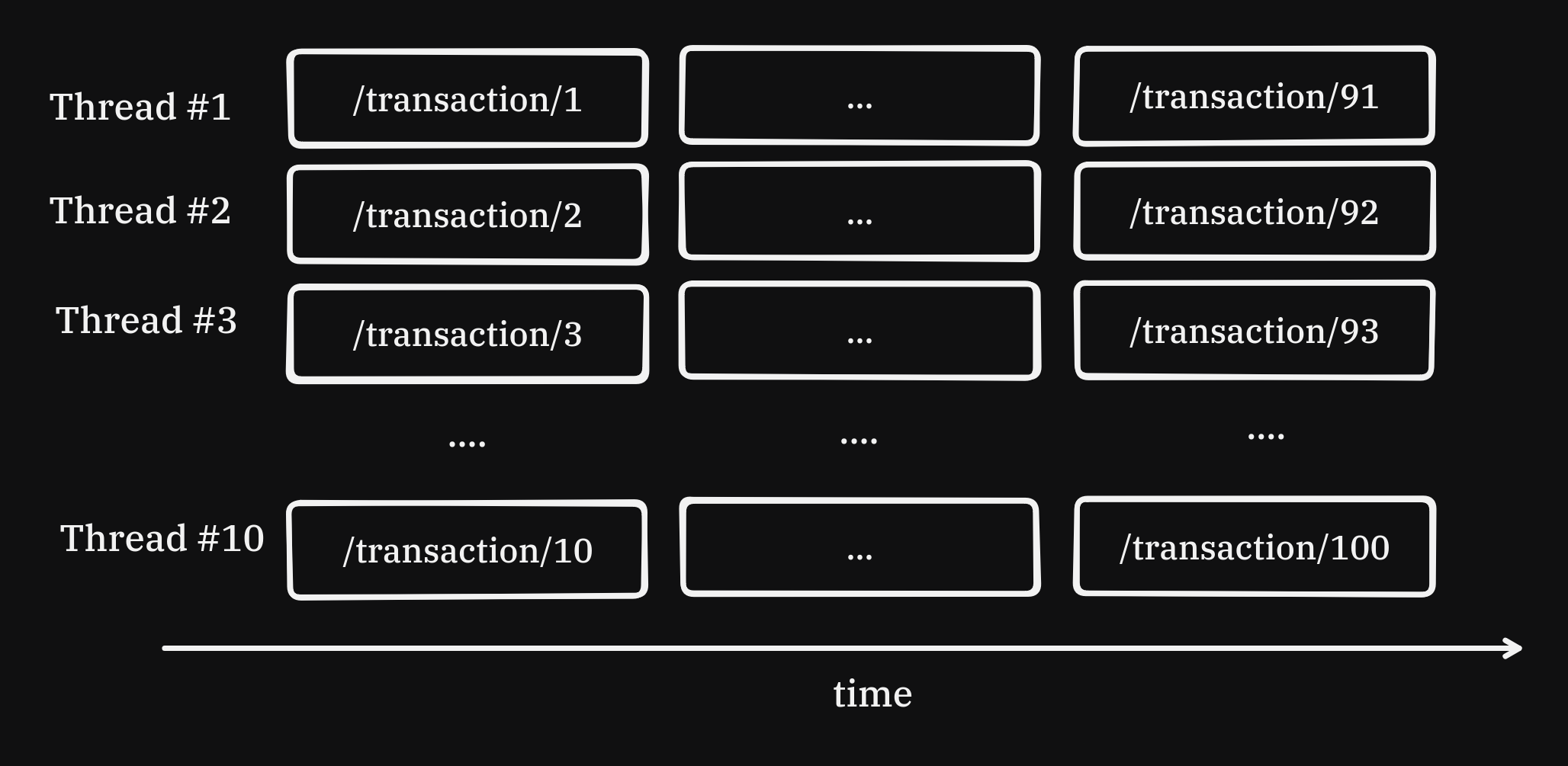
To maximise throughput, we must use CPU time efficiently by requesting transactions in parallel. Threads are one way to do this.
import requests
from concurrent.futures import ThreadPoolExecutor
url_list = [f"http://localhost:8000/transaction/{i}" for i in range(1, 101)]
def get_transaction(url):
if requests.get(url).status_code != 200:
raise Exception(f"Request {url} not successful!")
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(get_transaction,url_list)10 worker threads fetches 100 transactions in ; a 10x speed up:

1 million transactions will still take . For each thread, the OS allocates memory and spends time switching between them. This doesn't scale well for our needs. Thread safety becomes another challenge when dealing with writing the results to disk.
Corotines are light weight alternatives to threads.
Let's fetch 100 transactions using asyncio (python's coroutine module):
import asyncio
from aiohttp import ClientSession
url_list = [f"http://localhost:8000/transaction/{i}" for i in range(1, 101)]
async def get_transaction(url: str):
async with ClientSession() as session:
async with session.get(url) as response:
response = await response.read()
async def main():
tasks = []
async with asyncio.TaskGroup() as group:
for url in url_list:
group.create_task(get_transaction(url))
asyncio.run(main())
It takes only for 100 requests!
asyncio use cooperative multitasking to suspend blocking subprocesses. They are resumed once results are available. The asyncio event loop orchastrates this.

What about 1 million requests?
python requests_async.py
<truncated>
| raise client_error(req.connection_key, exc) from exc
| aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host
localhost:8000 ssl:default [Too many open files]We hit the file descriptor limit. We could increase this but we'll be greeted by the 10k problem. Semaphores limits the number concurrent async subprocesses.
Cristian Garcia writes about common gotchas when using them. We'll use his library pypeln to manage the task pool:
from aiohttp import ClientSession, TCPConnector
import asyncio
import sys
import pypeln as pl
limit = 1000
urls = [f"http://localhost:8000/transaction/{i}" for i in range(1, 1_000_001)]
async def get_transactions():
async with ClientSession(connector=TCPConnector(limit=0)) as session:
async def fetch(url):
async with session.get(url) as response:
return await response.read()
await pl.task.each(
fetch, urls, workers=limit,
)
asyncio.run(get_transactions())❯ python async.py
python async.py 987.19s user 91.26s system 89% cpu 20:06.85 total1 million requests in 20 minutes. That's about 200x faster than the original script. I'm eager to see how Rust or Go would compare against this. But this is good enough for now.
All about the size
For 100 blocks the script produces debug data. Thats for 100K blocks - too damn high!
The flattened csv has a lot of redundant data (block, tx hash, tx gas is repeated for each call-frame)
block,tx_hash,tx_gas,to,call_depth,memory_instruction,memory_access_offset,memory_gas_cost,pre_active_memory_size,post_active_memory_size,memory_expansion
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,1,MSTORE,0,6,0,32,32
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,1,MSTORE,20,6,32,64,32
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,1,MSTORE,21,3,96,96,0
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,1,MSTORE,4,3,96,96,0
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,2,MSTORE,64,12,0,96,96
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,2,MLOAD,64,3,96,96,0
20569001,0x82f6413a2658ebb83f27e44fe1e815ec0979a7dcc0bc9dbdbbbe058d547195a6,1051297,0x1f2f10d1c40777ae1da742455c65828ff36df387,2,MSTORE,64,3,96,96,0CSV is not an efficient file format, but it allows for rows to be appended which lowers the memory footprint of the script. Following optimizations were made to reduce the file size:
| Optimization | Total file size | Change |
|---|---|---|
| None | 512MB | 0 |
| Split the transaction and call frame data into separate csv files. | 86 MB | -83% |
| Encode: _ MSTORE as "W" (for "write [w]ord")_ MSTORE8 as "B" (for "write [b]yte")* MLOAD as "R" (for "[r]ead") | 72 MB | -16% |
Change CSV lineterminator from \r\n to \n. | 69 MB | -4% |
| Zip the csv files | 216 KB | -99.7% |
Pandas can read compressed zip file directly. Sweet.
You can check out the new and improved script™ here.
Next we run in prod and crunch some numbers.